ResiP
(Residual for Precise Manipulation), that sidesteps these challenges by augmenting a
frozen, chunked BC model with a fully closed-loop residual policy trained with reinforcement learning (RL)
that also overcomes the limitation of finetuning action-chunked diffusion policies with RL. The residual
policy is trained via on-policy RL, addressing distribution shifts and reactivity without altering the BC
trajectory planner. Evaluation on high-precision manipulation tasks demonstrates strong performance of
ResiP over BC methods and direct RL fine-tuning.
Modern chunked BC policies work well for planning trajectory segments but lack the corrective behavior and fine-grained reactivity needed for reliable execution.
Even massively scaling the dataset doesn't fully resolve it—Pure BC performance saturates even with 100K demos! Adding residual RL dramatically improves success rates with just 50 demos + RL fine-tuning.
Residual for Precise manipulationOur method, ResiP, adds closed-loop corrections via residual RL while keeping the base model frozen. As such, we effectively side-step all complications with applying RL to action-chunked and diffusion policies and retains all modes from pre-training.
The reward signal is only with a sparse task completion reward inferred directly from the demos and therefore requires no reward shaping.
By fine-tuning action-chunked diffusion policies with a per-step residual correction learned with online RL, we can drastically improve success rates for a range of multi-step tasks requiring precise alignments.
ResiP really shines on high-precision tasks. For a 0.2mm clearance peg-in-hole task, we improve from 5% → 99% success! The local nature of residual corrections is perfect for precise alignment.
How does it work? The residual policy learns to make small corrective adjustments to avoid common failure modes:
Finally, we demonstrate successful sim-to-real transfer by:
To fully appreciate the difference between imitation only and with the reactive controller learned with RL, please enjoy ~3-7 hours of rollouts per task at 4x speed below. This is 1000 consecutive rollouts for the different policies without any editiing or cherry-picking.
one_leg with low randomnessround_table with med randomnessWe present a pipeline for teaching robots to perform complex assembly tasks from RGB observations. The approach combines behavioral cloning (BC) and reinforcement learning (RL) techniques to develop robotic systems capable of precise manipulation.
The process involves training an initial policy through BC in simulation, enhancing it with RL, and then distilling the improved policy into a vision-based policy operating from RGB images. By integrating synthetic data with real-world demonstrations, we can create assembly policies that can be effectively deployed in the real-world.
This approach addresses challenges in robotic learning, including the need for high precision, adaptability to various initial conditions, and the ability to operate directly from visual data.

Fig. 1: (1) Beginning with a policy trained with BC insimulation, (2) we train residual policies to improve task success rates with RL and sparse rewards. (3) We then distill the resulting behaviors to a policy that operates on RGB images. (4) By combining synthetic data with a small set of real demonstrations, (5) we deploy assembly policies that operate from RGB images in the real world.
For long-horizon and complex tasks, modern policy architectural choices, like action chunks and diffusion, are necessary to achieve a non-zero task success from BC, which is necessary for downstream RL. However, this introduces complications for the RL finetuning. We opt for residual policies as a solution.
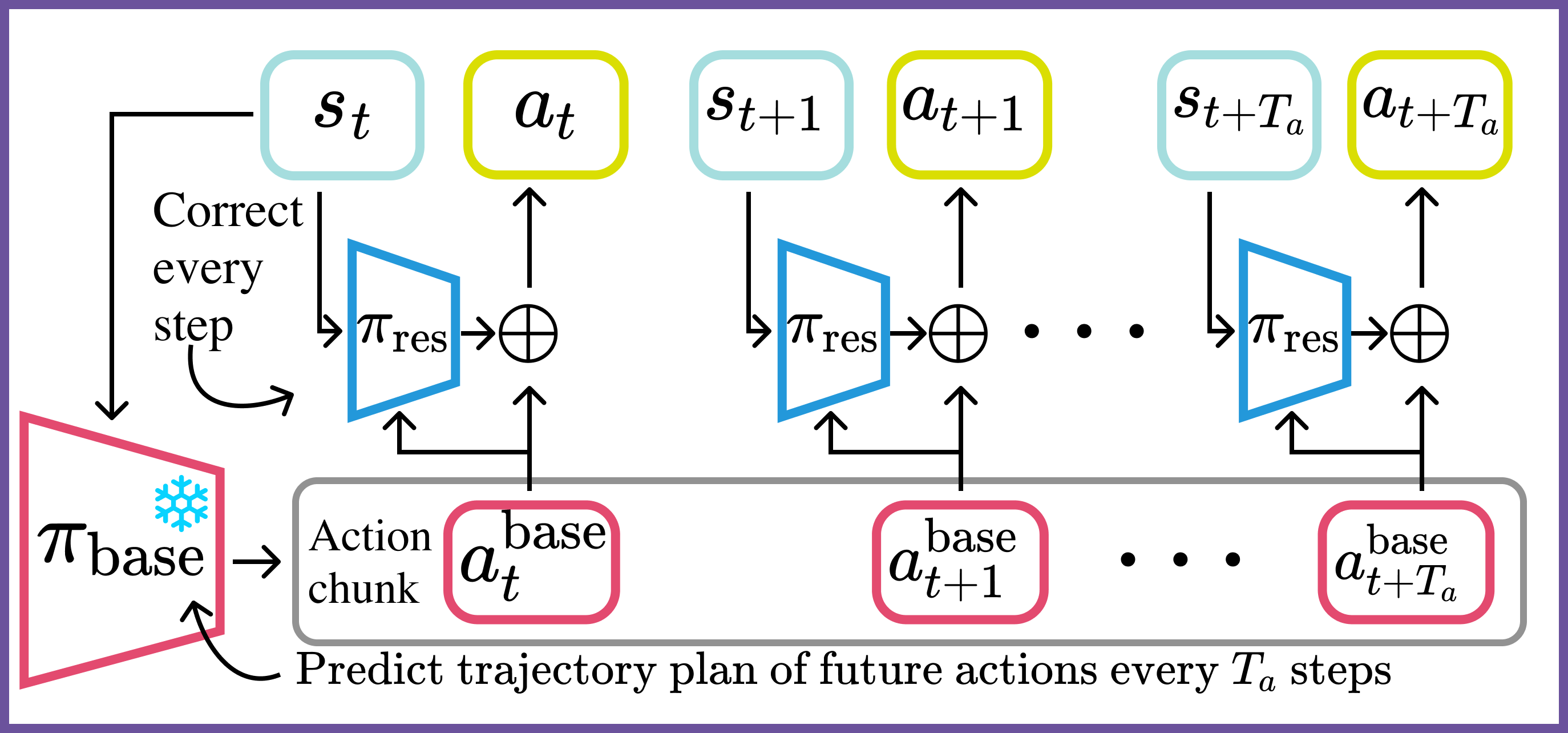
Per-timestep residual policies trained with PPO to locally correct action chunks predicted by a BC-trained diffusion policy:
This approach combines behavioral cloning and reinforcement learning, allowing flexible optimization without modifying the base model.

Fig. 2: Per-timestep residual policies trained with PPO to locally correct action chunks predicted by a BC-trained diffusion policy.
In the below videos, we visualize what the predictions made by the residuals look like and what the corrections do to the resulting net action. In the videos, the red line is the base action, the blue line is the residual prediction, and the green line is the resulting net action.
The peg comes down a bit to the right of the hole, and the base policy tries pushing the peg down, while the residual corrects the position so the insertion is successful.
The base policy tries to go down with the peg too deep in the gripper, which would probably have caused a colision between the right finger and the other peg. The residual pushes the gripper back so that it can get the peg between the fingers without collision.
Table 1 demonstrates the effectiveness of different approaches in robotic assembly tasks. Key findings include:
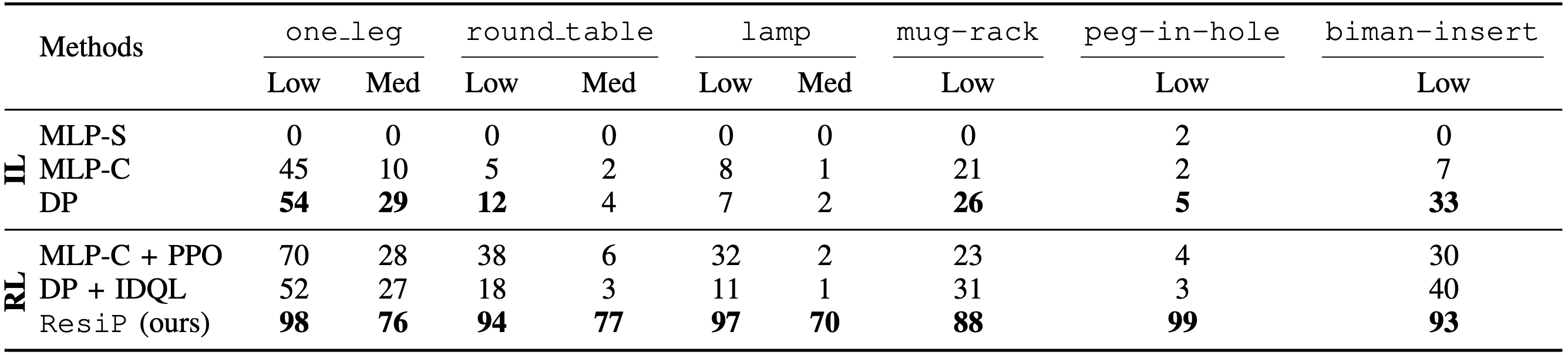
Tab. 1: Top BC-trained MLPs without chunking (MLP-S) cannot perform any of the tasks, and Diffusion Policies (DP) generally outperform MLPs with chunking (MLP-C). Bottom Training our proposed residual policies with RL on top of frozen diffusion policies performs the best among all evaluated fine-tuning techniques.
These experiments investigate the effectiveness of distilling a reinforcement learning (RL) policy trained in simulation into a vision-based policy for real-world deployment. The study focuses on how the quantity and quality of synthetic RL data impact the performance of the distilled policies. The experiments compare policies trained directly on human demonstrations with those distilled from RL agents, and explore the effects of dataset size and modality (state-based vs. image-based) on distillation performance.
Key Findings:

Fig. 4: Comparison of distilled performance from BC and RL-based teacher.

Fig. 5: BC distillation scaling with dataset size.
These experiments evaluate the performance of sim-to-real policies on the physical robot. The study compares policies trained on a mixture of real-world demonstrations and simulation data against those trained solely on real-world demonstrations. The quantitative experiments focus on the "one leg" task.
Key Findings:
These results demonstrate the effectiveness of combining real-world demonstrations with simulation data for improving the performance and robustness of robotic assembly policies in real-world settings.

Tab. 2: We compare the impact of combining real-world demonstrations with simulation trajectories obtained by rolling our RL-trained residual policies. We find that co-training with both real and synthetic data leads to improved motion quality and success rate on the one_leg task.
There's a lot of excellent work related to ours in the space of manipulation and assembly, reinforcement learning, and diffusion models. Here are some notable examples:
Recent work has explored combining diffusion models with reinforcement learning:
Learning corrective residual components has seen widespread success in robotics:
There's been an increasing amount of theoretical analysis of imitation learning, with recent works focusing on the properties of noise injection and corrective actions:
These works aim to enhance the robustness and sample efficiency of imitation learning algorithms.
Exciting future directions: Our method is base-model agnostic - we show it works with diffusion models, ACT, and MLPs!
This means it could potentially scale to fine-tuning large multi-task behavior models (like Octo, OpenVLA, etc.) while fully preserving their pre-training capabilities.
@misc{ankile2024imitationrefinementresidual,
title={From Imitation to Refinement -- Residual RL for Precise Assembly},
author={Lars Ankile and Anthony Simeonov and Idan Shenfeld and Marcel Torne and Pulkit Agrawal},
year={2024},
eprint={2407.16677},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2407.16677},
}
